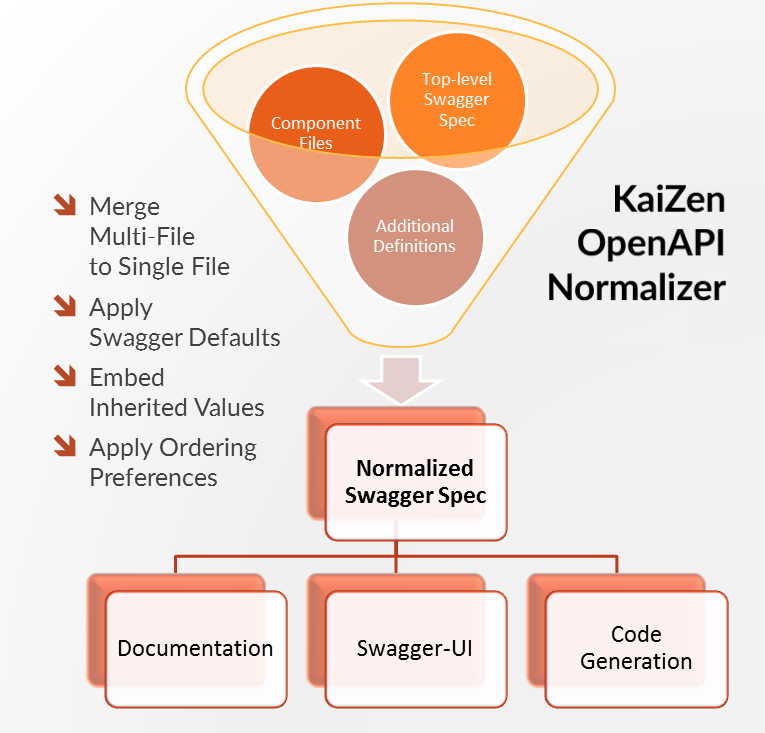
Using the KaiZen OpenAPI Normalizer GenTemplate
KaiZen OpenAPI Normalizer (formerly known as Swagger Normalizer) is a core component of the OpenAPI Multi-File Support in RepreZen API Studio, and as such it is used by each of the three “live” views - Documentation View, Diagram View, and Swagger UI View - that appear by default in the right-hand pane of the RepreZen API Studio GUI, as well as by all Swagger and OpenAPI v3 GenTemplates. You can also use it directly as its own GenTemplate, named “KaiZen OpenAPI Normalizer [YAML+JSON]” in the GenTarget Wizard.
The primary function of the normalizer is to render a multi-file OpenAPI model spec as a functionally equivalent single-file spec. In this way it can simplify the use of other tools and libraries in the evolving OpenAPI ecosystem, where external references are not always handled consistently.
Additionally, the normalizer can perform other transformations of the OpenAPI spec, which may be helpful for some circumstances, especially when feeding the spec to downstream systems.
Note: The term "Swagger" is a trademark of Smartbear Software and is the prior of some versions of the OpenAPI specification. In particular, "Swagger" is still commonly used to refer to version 2.0 of the OpenAPI Specification. In this document we will refer to this as "OpenAPI v2" wherever we need to refer specifically to that version of the specificaiton.
Basic Use
The Normalizer is used like any other OpenAPI GenTemplate:
-
Create a GenTarget (a
.genfile) in your model folder, linking your OpenAPI model file (.yamlfile) to the GenTemplate. The internal id of this GenTemplate is: [1]com.modelsolv.reprezen.gentemplates.swaggernorm.SwaggerNormalizerGenTemplateThe name listed in the drop-down list in the GenTarget wizard is “KaiZen OpenAPI Normalizer [YAML+JSON].” [2]
-
Configure the GenTarget as desired (see below).
-
Execute the GenTarget
-
Find the generated YAML file in the
generatedfolder that appears in the GenTarget folder.
Multifile Processing
The one thing that the normalizer will always do is resolve external references and leave you with a single-file OpenAPI Spec. The other things it may do depend on options, described in Normalizer Options.
References in OpenAPI Specs
Here’s an example of what a typical reference might look like in a OpenAPI spec:
responses:
default:
description: Default Response
content:
application/json:
schema:
$ref: "#/components/schemas/Pet"This is part of the definition of an operation whose normal response will contain data about
a pet. That information will be structured according to a schema named Pet defined elsewhere in
this same OpenAPI spec, in the components/schemas section of the spec.
The reference itself appears as the value of the schema property in the the response
content map. That property could appear with an "in-line" schema definition, but in this case the
designer has opted to define the schema elsewhere in the file and reference it here by name. The
reference itself takes the form of an object with a string-valued property named
$ref. [3]
If the definition of the Pet schema physically appeared in some other model spec, the reference
would need to include a URL to retrieve that spec, with a fragment identical to the reference string
shown above:
responses:
default:
description: Default Response
content:
application/json:
schema:
$ref: "http://models.example.com/petstore-schemas.yaml#/components/schemas/Pet"
OpenAPI’s $ref syntax conforms to a separate standard known as "JSON Reference." That
standard is available here.
|
Conforming and Non-Conforming References
References in an OpenAPI spec should all be of the variety specifically endorsed by the OpenAPI Specification. We’ll call those conforming references. All other references will be called non-conforming references.
The precise definition differs between v2 and v3 of the specification, but in both cases, the definition depends on prefixes of the fragment portion of the reference string.
v2 Conforming Prefixes |
v3 Conforming Prefixes |
|
|
|
|
Normalizer does not treat conforming and non-conforming reference identically.
What the Normalizer Does with References
When the normalizer encounters any reference, there are two ways it may process the reference:
- Inline
-
The normalizer retrieves the referenced value (e.g. the
Petschema definition object) and replaces the reference itself with that value. - Localize
-
The normalizer first adds the referenced object to the normalized spec that it is creating, if it is not already present, and then replaces the reference with a local reference to that object. So in the external reference example shown above, the
Petschema definition would appear directly in the OpenAPI spec produced by the normalizer, and references that were formerly external references would become local references.
The normalizer always inlines non-conforming references. Any given conforming reference might be inlined or localized, depending on options in effect.
Name Collisions
Localization of a conforming reference may lead to a name collision. For example, imagine the following excerpts from two OpenAPI specs:
main.yaml
components:
schemas:
Address:
description: An address given by a speaker
type: object
properties:
speaker:
$ref: "external.yaml#/components/schemas/Person"
title:
type: string
...external.yaml
components:
schemas:
Person:
name:
type: string
address:
$ref: "#/components/schemas/Address"
Address:
description: A postal address
type: object
properties:
street:
type: string
...The main spec is apparently describing APIs related to events where speakers deliver addresses. The
speakers themselves are represented using an externally referenced Person schema which itself
makes use of a locally referenced Address schema.
In a localizing scenario, the normalized spec created by the normalizer would look something like this:
main-normalized.yaml
components:
schemas:
Address:
description: An address given by a speaker
type: object
properties:
speaker:
$ref: "#/components/schemas/Person" (1)
title:
type: string
...
Person:
name:
type: string
address:
$ref: "#/components/schemas/Address_1" (2)
Address_1:
description: A postal address
type: object
properties:
street:
type: string
...The two Address schemas originally in main.yaml and external.yaml are both needed in the
normalized spec, but their names collide. Therefore, the schema definition originally in
external.yaml is renamed to Address_1.
All references have been adjusted as required:
| 1 | The former external reference to the Person schema is now a local reference. |
| 2 | The Person schema’s Address reference now reflects the renaming that occurred. |
Renaming is done only where necessary due to a conflict, and the names appearing in the top-level
spec are always preserved as-is; that is, if there is a colliding externally referenced object that
needs to be localized, that object will be renamed, not the top-level object with which it
collided. In the above example, the Address schema occurring in main.yaml will always retain its
original name, forcing any colliding objects to be renamed.
Recursive References
It is possible to set up recursive schema definitions in OpenAPI specs, through the use of references. For example, consider the following schema:
components:
schemas:
Person:
type: object
properties:
name:
type: string
children:
$ref: "#/components/schemas/People" (1)
People:
type: array
items:
$ref: "#/components/schemas/Person" (2)| 1 | The Person schema has a children property of type People,
and |
| 2 | the People schema defines an array of Person objects. |
Naively attempting to inline a reference to a Person object would
lead to a never-ending expansion like this:
original
matriarch:
$ref: "#/components/schemas/Person"inlined
matriarch:
type: object # inline Person
properties:
name:
type: string
children:
type: array # inline People
items:
type: object # inline Person
properties:
name:
type: string
children:
type: array # inline People
items:
type: object # inline Person
... # inlining never endsWe have cut off the inlining above with an ellipsis, but in reality it could never stop.
To handle recursive references encountered during inlining, the normalizer stops inlining whenever a reference is encountered that is fully contained within another (inlined) instance of the referenced object. That recursive reference is localized rather than being inlined.
In the above example, we would end up with something like this:
partially-inlined
matriarch:
type: object (1)
properties:
name:
type: string
children:
type: array
items:
$ref: "#/components/schemas/Person" (2)
...
components:
schemas:
Person:
type: object
properties:
name:
type: string
children:
type: array
items:
$ref: "#/components/schemas/Person" (3)
...Here we see:
| 1 | that the top-level reference to Person as the type of the matriarch property was inlined; |
| 2 | that the recursive reference to Person encountered while performing this inlining has been
localized; |
| 3 | that the Person schema itself was subjected to inlining, with localization of its recursive
reference; |
Note that the People schema never ran into a recursive reference during inlining (though that
could have happened, e.g. if matriarch had a parents property of type People). Therefore it
was not localized.
When an object is inlined without encountering a recursive reference (so that the object is not also
localized), we say that it is fully inlined. This was the case for People above.
| For non-conforming references, recursion is not currently permitted and will cause the normalizer to fail. |
Object Retention
Some of the normalizer options pertain to object retention policy: rules that decide which objects from the multifile spec will appear in the normalized output.
The Completeness Rule
In all cases, the normalized spec must be complete, in the sense that all references appearing in the spec resolve to objects defined in the spec.[4] Thus, any object that is referenced in the normalized spec is also retained in the normalized spec.
Objects that are fully inlined are not required by the completeness rule and may not be retained, depending on options in effect. An object that is partially inlined because of recursive references is required by completeness, since recursive references are localized. Such an object must be retained.
All other retention policy is subordinate to completeness: every referenced object is retained, even if other retention policy would cause it to be dropped.
Root Objects
Completeness presupposes a starting point: some set of objects that are retained for other reasons. References appearing in those objects are processed for completeness, and then objects that are retained for completeness are themselves processed for completeness, and so on.
We call the objects that are retained for reasons other than completeness root objects. Root objects are determined according to retention policy and retention scope, as defined by options.
Retention Policy
Retention policy is determined according to RETAIN and DROP rules that select and reject individual objects. An object is retained if it matches at least one RETAIN rule and does not match any DROP rule.
Currently, there is only one RETAIN rule, which specifies which object types - paths, schemas, parameters, responses, etc. - are to be retained. There are not currently any DROP rules implemented. We anticipate implementing additional RETAIN and DROP rules in the future to provide additional flexibility.
Object-type-based retention policy is specified with the RETAIN option.
Retention Scope
Retention policy is applied only to objects that appear in files that are considered in scope for retention. The top-level file is always in scope.
When processing an OpenAPI spec, other specs may be loaded in order to satisfy references. By default, those other specs are not in scope. However, if the RETENTION_SCOPE option is set to ALL, specs that are loaded solely to resolve references will also be considered in scope, so that other objects in those files may be retained - even if they are not needed for completeness.
It is also possible to identify other files to be treated as top-level for retention purposes, by listing them in the ADDITIONAL_FILES option.[5] All such files will be loaded and will be in-scope for retention, regardless of whether any objects they contain are otherwise required for completeness. And of course, retained references from those files will be processed for completeness.
|
One important use-case for "additional files" involves If the subtypes are defined in a separate file, that file will not be loaded for reference resolution, and so those subtypes will not be loaded—let alone retained—by the normalizer. Configuring the file as an "additional file" would cause the file to be loaded, and subtype definitions would then be eligible for retention. |
Normalizer Options
When the normalizer is used through its GenTemplate ("KaiZen OpenAPI Normalizer [YAML+JSON]"),
options are configured in the GenTarget file — the .gen file created by the GenTarget
wizard. Each option can take on various values, as detailed below.
Options are as follows:
- INLINE
-
Specify which objects are inlined by the normalizer. The value of this option can be:
-
A list of non-PATH object types, drawn from the types relevant to the model version.[6]
-
For v3 models, this includes SCHEMA, RESPONSE, PARAMETER, EXAMPLE, REQUEST_BODY, HEADER, SECURITY_SCHEME, LINK, and CALLBACK.
-
For v2 models, this includes DEFINITION, PARAMETER, and RESPONSE.
-
-
The value ALL, meaning that all objects are inlined.
-
The value COMPONENT, meaning that all objects except paths are inlined.[7]
-
The value NONE, meaning that no objects (except paths) are inlined.
-
- RETAIN
-
Specify which object types will be retained from in-scope files. The value of this option can be:
-
A list of object types relevent to the model type (same as for INLINE, but also including PATH).
-
The value ALL, meaning that all objects are retained.
-
The value COMPONENT, meaning that all objects except paths are retained.
-
The value PATH_OR_COMPONENT [8], meaning that:
-
If the top-level spec defines at least one path, then the PATH option will be in effect.
-
Otherwise, the COMPONENT option will be in effect.
-
-
- RETENTION_SCOPE
-
Determines which OpenAPI model specs are considered in-scope for retention rules. Value is either:
-
ROOTS, meaning that only the top-level file and any files specified in ADDITIONAL_FILES will be in scope; or
-
ALL, meaning that files loaded in order to resolve references will also be considered in scope.
-
- ADDITIONAL_FILES
-
Specifies additional files that should be treated as top-level for retention, and are therefore always loaded and always in-scope. The value is a list of file names, or more generally URLs. Each URL, if it is relative, is resolved based on the URL that specifies the top-level file.
Swagger-Only Options
The following options currently apply only to Swagger (i.e. OpenAPI v2) model specs. They address
perceived shortcomings in SwaggerParser and its associated Swagger object model and API.
- HOIST
-
Enables some or all of the hoisting operations that can be performed by the normalizer. Hoisting refers to extrapolating certain items appearing in a Swagger spec into the contexts in which they apply. The option value is a list of hoistable items, drawn from:
-
MEDIA_TYPE: Global
consumesandproducesdeclarations are extrapolated into all operations that do not contain their own declarations. -
PARAMETER: Parameters defined at path-level are extrapolated into every operation appearing in the path that does not already define a parameter with the same name and the same
invalue. -
SECURITY_REQUIREMENT: The global security requirements array is extrapolated into every operation that does not define its own.
The HOIST option value may also be ALL or NONE.
-
- REWRITE_SIMPLE_REFS
-
In former versions of the Swagger specification, reference strings were allowed to take a simple form like
Pet. These would be treated as internal references based on the context in which the reference appears. For example, in old pet-store examples, references to thePetschema appeared simply as$ref: Petand this would be equivalent to$ref: #/definitions/Pet.While these “simple references” are no longer supported by the Swagger specification, they are still processed by some existing tools. Enabling this option will cause the normalizer to rewrite simple references to fully compliant internal references.[9]
The REWRITE_SIMPLE_REFS option value should be either true or false.
- CREATE_DEF_TITLES
-
This option causes the normalizer to add
titleproperties to definitions that do not already have them. The title for such a definition is set to its property name in thedefinitionsobject of its containing Swagger spec.This is particularly helpful when name collisions occur during localization, as the titles then reflect the original names of the definitions, prior to renaming. The CREATE_DEF_TITLES option value should be either true or false.
- INSTANTIATE_NULL_COLLECTIONS
-
There are many optional properties in the Swagger specification, and the Swagger Java parser creates structures in which omitted properties generally appear with
nullvalues. This forces a great deal of null-checking in Java code that processes parsed Swagger specs. The INSTANTIATE_NULL_COLLECTIONS option causes such null values for either array-valued or object-valued properties to be replaced with empty arrays and objects, respectively, where doing so would not alter the meaning of the spec.[10]The INSTANTIATE_NULL_COLLECTIONS option value should be either true or false.
- FIX_MISSING_TYPES
-
The Swagger Java parser accepts Swagger specs in which some object schemas are missing their
typeproperty. This is allowed when the schema contains either apropertiesoradditionalPropertiesproperty, and the parser treats the schema as if it containedtype: object. This option causes the normalizer to explicitly addtype: objectin these schemas.The FIX_MISSING_TYPES option value should be either true or false.
- ORDERING
-
This option gives you some control over the order in which objects appear in the model spec produced by the normalizer. Permitted values include:
-
AS_DECLARED, meaning that there should be no reordering of the model elements by Normalizer. This applies only to objects declared in the top-level and other root files; objects localized or retained from other files will appear after all root file objects, but not in a predictable order.
-
SORTED, meaning that a mostly-alphabetical ordering is imposed within the output model. In this case, all objects from all files participate, not just those from root files. The details of this ordering are as follows:
-
Paths, global parameters, global responses, and schema definitions are all ordered in a quasi-alphabetic order based on their names in the normalized spec. This is a case-insensitive ordering, except that names of the form Xxx_nnn are treated specially, where nnn is a numeric suffix. Such names are typically the result of disambiguation when collisions occur through localization. However, if your models use such names on their own, they will be treated the same way by the ordering algorithm.
When such names occur, ordering is such that all names with the same root - including the unadorned root itself - appear together, and with numerically increasing suffixes. This is the case even when two roots differ only by letter case.
For example, you would always see the following names in the indicated order:
FOO, FOO_1, FOO_2, …, FOO_10, Foo, Foo_1, Foo_2, …, Foo_10 -
Operations within a path are ordered in the standard sequence defined by the Swagger project’s
Swaggerclass:get, head, post, put, delete, options, patch -
Responses defined within an operation are sorted numerically by response code, with a
defaultentry, if any, following all numeric entries.
-
-
With both treatments - even SORTED - ordering is restricted to the model contents specifically mentioned above. So, for example, tags, operation parameters, object schema property lists, and the top-level structure of the swagger spec should mostly be as they are in the source spec under both ordering treatments, except where Swagger project software may disrupt things (e.g. in the ordering of top-level model sections).
The way to interpret the above paragraph in the case of AS_DECLARED ordering is that the Normalizer will not record positional information for items not explicitly mentioned in the details of the SORTED ordering. Therefore, if these items are reorganized by Swagger software, it will not be possible to reconstruct the original ordering.
In some cases these unaddressed orderings are likely to become addressed by the normalizer in a future release, but we have explicitly chosen not to reorder parameter lists in operations, since doing so could cause incompatible changes in the output of certain code generators (e.g. in generated method signatures).
Option Defaults
The normalizer is used in RepreZen API Studio in the following scenarios:
-
Loading an OpenAPI spec for display in one of the live views: Diagram, Documentation, and Swagger UI.
-
Loading an OpenAPI spec for processing by a GenTemplate other than the "KaiZen OpenAPI Normalizer [YAML+JSON]" GenTemplate.
-
Loading an OpenAPI spec for processing by the "KaiZen OpenAPI Normalizer [YAML+JSON]" GenTemplate.
The following table specifies the option settings that are used in each case:
| Option | Documentation Live View | All Other Scenarios |
|---|---|---|
INLINE |
PARAMETER, RESPONSE |
PARAMETER, RESPONSE |
RETAIN |
PATH_OR_COMPONENT |
ALL |
RETENTION_SCOPE |
ROOTS |
ROOTS |
ADDITIONAL_FILES |
empty |
empty |
HOIST |
ALL |
ALL |
REWRITE_SIMPLE_REFS |
true |
true |
CREATE_DEF_TITLES |
true |
false |
INSTANTIATE_NULL_COLLECTIONS |
true |
true |
FIX_MISSING_TYPES |
true |
true |
ORDERING |
AS_DECLARED |
AS_DECLARED |
Note that the Document Live View defaults differ from all the rest, including other live views.
There is currently no way to alter the option settings for any scenario except the "KaiZen OpenAPI Normalizer [YAML+JSON]" GenTemplate, where the GenTarget file explicitly sets all option values. The New GenTarget wizard in RepreZen API Studio creates a GenTarget with option values set initially according to the "All Other Scenarios" column above, and you may edit those options as desired.
1. Note that the internal id reflects the fact that the normalizer was initially developed prior to the creation of the OpenAPI Initiative, and we have retained the original id for backward compatibility.
2. Note that the internal id reflects the fact that the normalizer was initially developed prior to the creation of the OpenAPI Initiative, and we have retained the original id for backward compatibility.
3. Local references like this one - that is references to an object in the same file - always start with a pound sign: "#". This happens to be the comment character in YAML syntax, so a common error is to omit quotes around the reference string. This will have the same effect as an empty string, which can lead to a variety of problems with consumers of the model. Be careful to always use quotes around your reference strings!
4. The only exception to this is references that could not be resolved in the original spec; these will be copied as-is into the normalized spec.
5. The only difference between these files and the actual top-level file has to do with object renaming. As stated earlier, objects appearing in the top-level spec will never be renamed. However, it is possible for a name collision to occur when loading "additional" files, and such collisions will trigger object renaming. Additional files are loaded immediately after the top-level file, in the order in which they are specified, and naming priority always favors the earlier-loaded files.
6. PATH is not an option because paths are always inlined; local path references are disallowed in OpenAPI specs.
7. This option is really equivalent to ALL, since paths are always inlined anyway; no other treatment is sensible since local path references are not allowed in an OpneAPI spec.
8. This option is needed for our Reprezen HTML Documentation gen target, which inlines everything by default and retains only top-level paths, except when there are no paths; in that case it still inlines everything, but it also retains everything.
9. Simple reference strings are recognized only if they start with an alphabetic character or “_” and consist solely of alpha-numeric characters and “_”.
10. An example of where such replacement would change the spec is the
consumes and produces arrays in operation definitions. For these, an empty array would prevent inheriting the corresponding global defaults, while a null value would not.