|
<< Click to Display Table of Contents >> Customizing Data Type Realization |
  
|
|
<< Click to Display Table of Contents >> Customizing Data Type Realization |
|
This section describes basic canonical data model realization beyond decorated hyperlinks.
UML defines realization as the relationship between a specification and its implementation. In RepreZen API Studio, a data structure serves as an abstract specification, and the first step towards implementation is to adapt that structure to the context in which it is used. This topic describes some of the specific ways in which we can customize the canonical data types in the context of API resources:
| • | Property Subsets - when we only want to use a subset of a structure's properties |
| • | Cadinality Overrides - when the cardinality of a structure's property needs restricting |
The important thing to note, here, is that data type realizations really become useful, and make the most sense, when data models are shared across APIs. In these cases, the data model we are using is not owned by us, and does not reside in the same rapidModel with our API, but is being imported from some central location. Such data models are abstract and, in the best case, are really models of the business domain. In an ideal world, shared models won't be specific to an application, service or technology; they will be more or less generic descriptions of the business domain we are working in. They may be very detailed in the information they describe, but they should be technology independent and, as much as we can make them so, they should be context-neutral, which maximizes their potential value for reuse. However, to unlock this potential, we need to be able to tailor these data models for a variety of specific uses.
We'll start off by looking at property subsets - a realization technique that enables us to use a limited collection of properties from a structure in our data model.
Property subsets
At this point in our TaxBlaster demo we have defined the following data types: TaxFiling, Person and Index. We also have some resources that are bound to the types we have defined. But there are some cases where we want to be able to customize this a little bit. For instance, the Person data type may be too detailed for our particular use case, or too broad in its definition. And although our TaxFiling structure so far only contains seven or eight properties, in a real situation we might find that a TaxFiling has 70, 80, or more. In our particular service it may be overkill to include all those things. It may even be worse than overkill because some of that information could be sensitive and therefore inappropriate to expose to the people who are using this service, or there could be properties that we don't want to make available for modification.
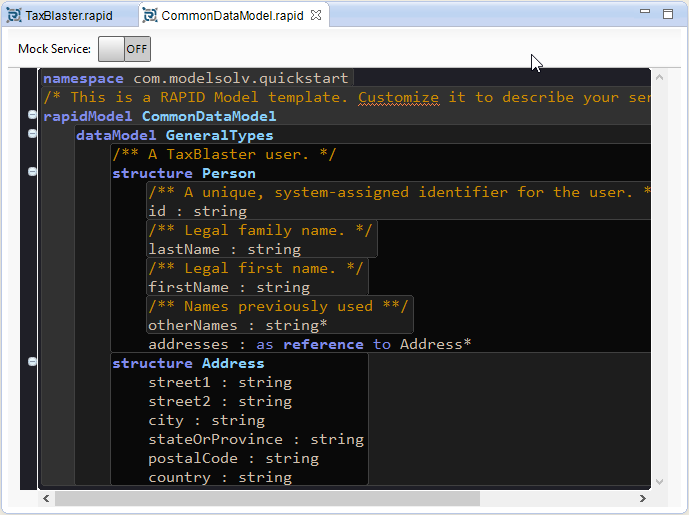
To make this more interesting, let's add a new structure to our common dataModel called Address:
structure Address
street1 : string
street2 : string
city : string
stateOrProvince : string
postalCode : string
country : string
Next, we'll add a list of addresses as a property to our Person structure. (The * cardinality indicator denotes that a Person can have zero or more instances of Address.)
structure Person
/** A unique, system-assigned identifier for the user. */
id : string
/** Legal family name. */
lastName : string
/** Legal first name. */
firstName : string
/** Names previously used **/
otherNames : string*
addresses : as reference to Address*
Our common data model should now look like this:
And the relationship between TaxFilingObject and PersonObject in our diagram will now look like this:

Note: the new addresses property of Person is fully embedded within the PersonObject resource rather than being depicted as a hyperlink. This is because there is no resource (yet) for specifically accessing Address type data. What's more we see all the properties of the Address structure are present.
Now, let's add an itemized property set to the TaxFilingObject resource so that we only get the properties of Address we actually need in this context.
| 1. | In the TaxFilingObject resource put a few newlines between the URI and referenceLink elements, place the cursor in the resulting space at the same indent level as URI. Press Ctrl+Space and select property set (itemized) from the list of code assist templates: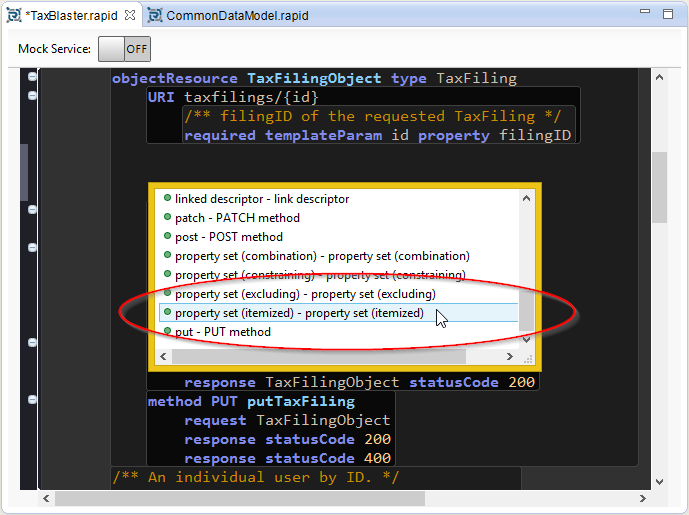 |
| 2. | When the template expands press Enter to accept the default. Then press Ctrl + Space again and select the full list of properties: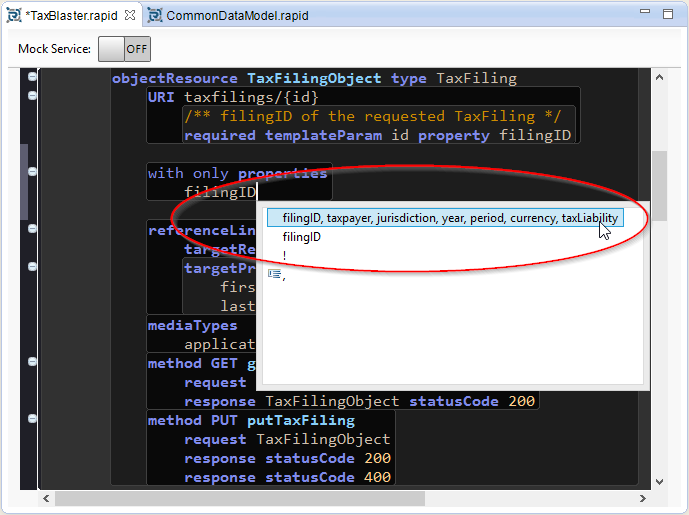 |
| 3. | Now press Ctrl+Shift+F to reformat the code and put the properties each on a newline: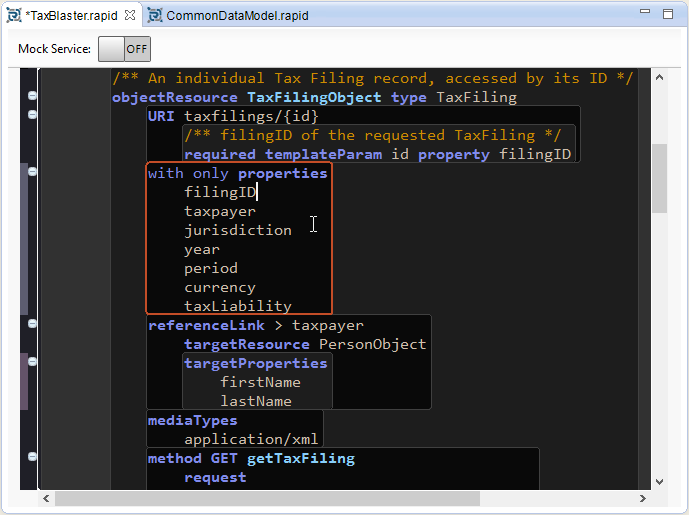 |
| 4. | Now we'll remove the properties we don't care about, or wish to omit, in this context. So delete jurisdiction, currency and taxLiability from the list. (You can use Ctrl+D in the editor to delete the current line.) If we look at our TaxFilingObject in the API diagram now it should look like this: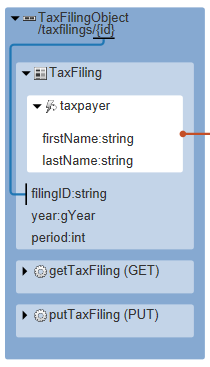 |
We can further refine the use of property subsets using embedded representations. Below the subset we just created is a referenceLink we added earlier. With a referenceLink we realize a reference (in this case taxpayer) as a hyperlink to the resource that's bound to the target data type (in this case Person). On the other hand, if we just want to embed the data directly, with no hyperlink, we can use a referenceEmbed element instead.
| 1. | Let's change the taxpayer referenceLink to a referenceEmbed so that goes from looking like this: referenceLink > taxpayer targetResource PersonObject targetProperties firstName lastName to looking like this: referenceEmbed > taxpayer |
| 2. | The TaxFilingObject in our diagram now looks like this: Instead of being a decorated hyperlink to the PersonObject resource, the Person structure is now an embedded object with its complete property set. Notice that, because Person includes a reference to a list of Address type properties, we can see another level of embedding here, too. |
| 3. | Let's refine this still further by adding a targetProperties element to our referenceEmbed to trim the list of Person properties down a bit. Using code completion, start again with the full list of attributes from Person: |
| 4. | Press Ctrl+Shift+F again to reformat the code, which makes it easier to trim out the properties we don't want. |
| 5. | Let's say that, in this context, we don't care about the otherNames property, so we'll remove it from the list, leaving our diagram like this: This seems reasonable. But let's say that addresses is actually more detailed than we need. We can now do a recursive referenceEmbed that can include a targetProperties specification where we can get rid of the Address properties we don't want. |
| 6. | Put the cursor at the bottom right hand corner of the targetProperties element we just added to the taxpayer referenceEmbed, press Enter, then Backspace to leave the cursor here: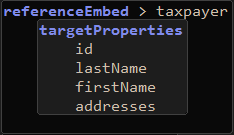 |
| 7. | Use Code Assist to add another referenceEmbed at this location, inside the first one, like so: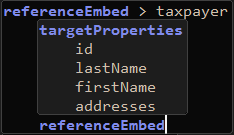 |
| 8. | Add a Space and use Code Assist, twice, to complete the line like this: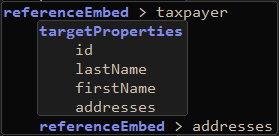 |
| 9. | Now we'll filter out the properties we don't want from Address in this context using targetProperties again. For instance, city, stateOrProvince and country may be the level of detail that is appropriate here: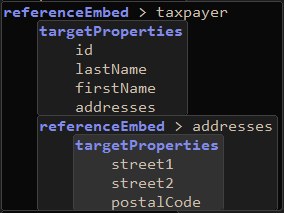 |
| 10. | The diagram, again, allows us to sanity check our model after these changes:  |
Note: The customizations we have just applied only affect the realization of Person type data in the context of the TaxFilingObject resource. If you look at Person and Address data in the PersonObjectResource you can still see the full set of properties.
Now, let's review the nested structure we have just created:
| 1. | Our root object, here, is TaxFiling. |
| 2. | We use a property subset to include the TaxFiling properties we want, one of which is taxpayer. |
| 3. | Then we use a referenceEmbed with targetProperties to specify the subset of Person properties that we want to include for a taxpayer. |
| 4. | Finally, we go one level deeper and say that, with the addresses included for a taxpayer, we only want a subset of three properties. |
The RepreZen API Studio language allows us to customize the realization of data types like this, to whatever level of detail is needed for a specific application, right down to the leaf level.
Property subsets are one way in which we can customize the realization of data types. In the next section we'll look at another important example: cardinality overrides.
Cardinality Overrides
Sometimes we have contextual constraints. The cardinality indicator on the addresses reference property in the Person type is 'zero or more' but it could be that, in our particular service, we need at least one address for a taxpayer, or things just won't work correctly. To achieve this we simply specify a property set in our PersonObject resource, and override the cardinality on the addresses attribute like this:
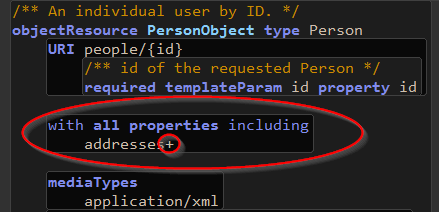
Note: In this release of RepreZen API Studio, we can perform cardinality overrides in the context of the resource bound to the data type in question. We cannot yet, for instance, do this from within the taxpayer referenceEmbed we added to the TaxFilingObject resource.
You may bend the rules (but not break them)
Data type realization techniques enable us to adapt a data type for our purposes within logical limits. So, cardinality overrides may be used to narrow existing constraints but they cannot be used to broaden them, as this would break the rules of the underlying data type.
The default constraint on all attributes is 'zero or more', which makes for flexibility. If we update the cardinality of the lastName property in our Person structure to 'exactly one'
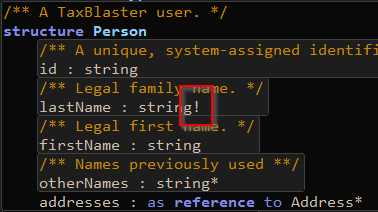
and then try to make the lastName property in our PersonObject resource optional, we will get an error:

If we were trying, for example, to insert a new Person record without a lastName we would be violating the rules of the canonical model.
Note: RepreZen API Studio supports other forms of contextual constraint beyond cardinality overrides. To find out about these, and where they can be used, please see the Language Specification and/or Quick Reference Card which are accessible from the Help menu.
| Copyright © 2016 ModelSolv, Inc. All rights reserved. RepreZen and RAPID-ML are trademarks of ModelSolv, Inc. Swagger is a registered trademark of SmartBear Software, Inc. RepreZen API Studio is not associated with nor endorsed by SmartBear Software, Inc. |